ReconDreamer:Crafting World Models for Driving Scene Reconstruction via Online Restoration
- Chaojun Ni*1,2
- Guosheng Zhao*1,4
- Xiaofeng Wang*1,4
- Zheng Zhu*1✉
- Wenkang Qin1
- Guan Huang1
- Chen Liu3
- Yuyin Chen3
- Yida Wang3
- Xueyang Zhang3
- Yifei Zhan3
- Kun Zhan3
- Peng Jia3
- Xianpeng Lang3
- Xingang Wang4
- Wenjun Mei2✉
- 1 GigaAI
- 2 Peking University
- 3 Li Auto Inc.
- 4 CASIA
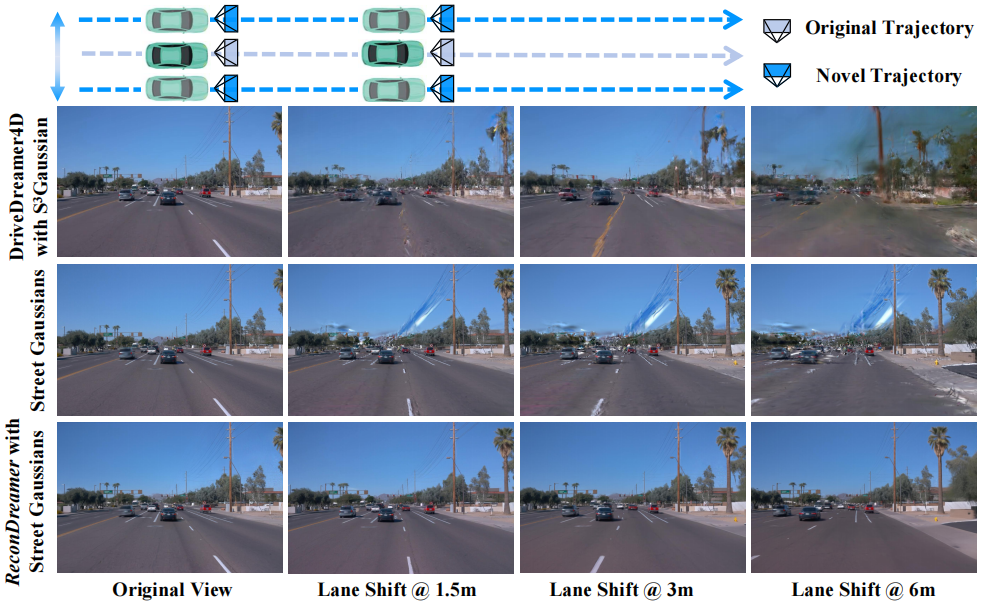
Dynamic driving scene reconstruction methods, such as DriveDreamer4D and Street Gaussians, encounter significant challenges when rendering larger maneuvers (e.g., multi-lane shifts). In contrast, the proposed ReconDreamer significantly improves rendering quality via incrementally integrating world model knowledge.
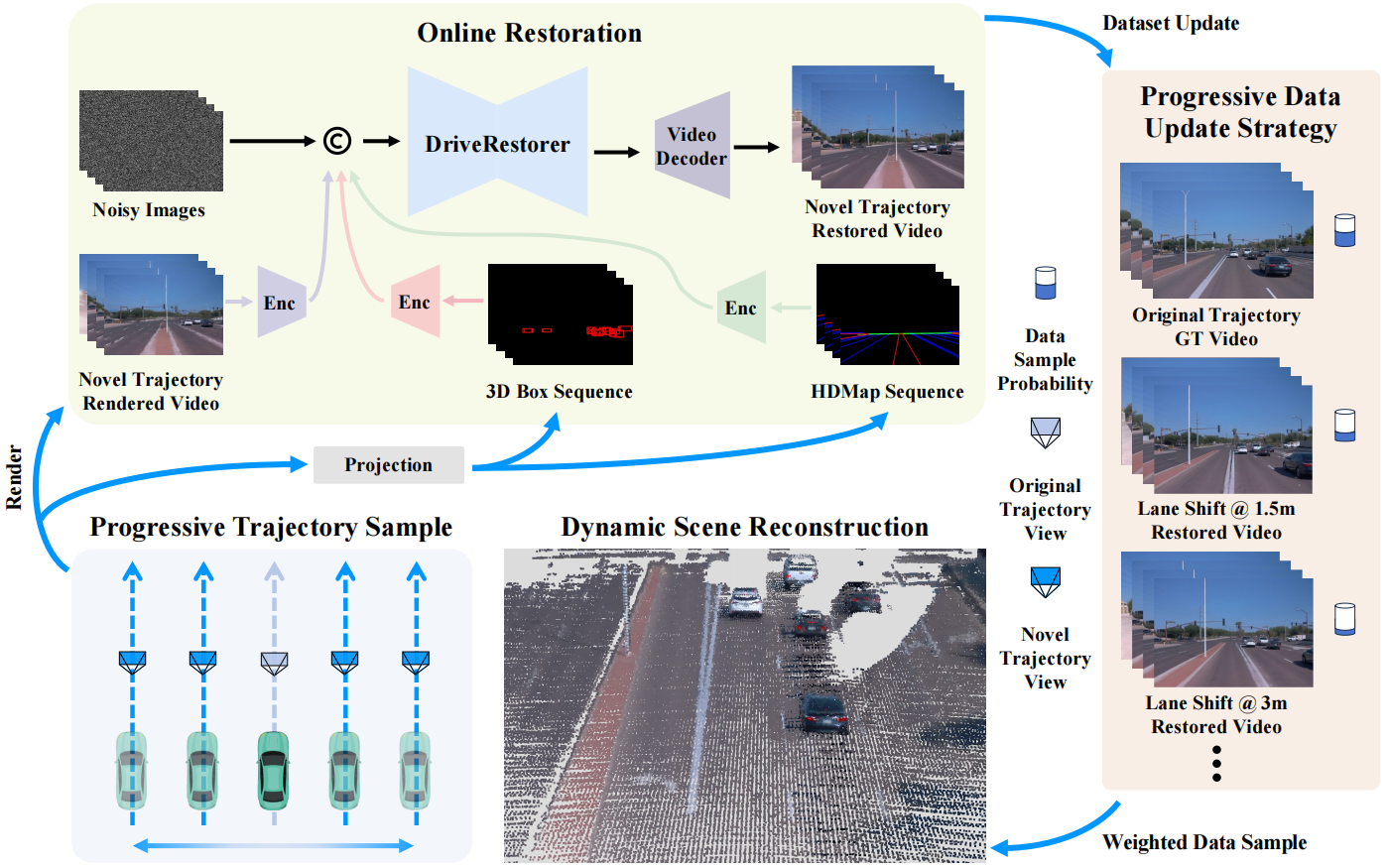
The overall framework of ReconDreamer. During the training of the dynamic driving scene reconstruction, we begin by rendering novel trajectory views. These rendered videos are subsequently processed by the DriveRestorer to restore their quality. Then these restored videos, together with the original video, are employed to optimize the reconstruction model. This iterative process continues until the reconstruction model converges.
Abstract
Closed-loop simulation is crucial for end-to-end autonomous driving. Existing sensor simulation methods (e.g., NeRF and 3DGS) reconstruct driving scenes based on conditions that closely mirror training data distributions. However, these methods struggle with rendering novel trajectories, such as lane changes. Recent works have demonstrated that integrating world model knowledge alleviates these issues. Despite their efficiency, these approaches still encounter difficulties in the accurate representation of more complex maneuvers, with multi-lane shifts being a notable example. Therefore, we introduce ReconDreamer, which enhances driving scene reconstruction through incremental integration of world model knowledge. Specifically, DriveRestorer is proposed to mitigate artifacts via online restoration. This is complemented by a progressive data update strategy designed to ensure high-quality rendering for more complex maneuvers. To the best of our knowledge, ReconDreamer is the first method to effectively render in large maneuvers. Experimental results demonstrate that ReconDreamer outperforms Street Gaussians in the NTA-IoU, NTL-IoU, and FID, with relative improvements by 24.87%, 6.72%, and 29.97%. Furthermore,ReconDreamer surpasses DriveDreamer4D with PVG during large maneuver rendering, as verified by a relative improvement of 195.87% in the NTA-IoU metric and a comprehensive user study.